人工智能资讯 第40页
聚合当前分类下的最新内容,按时间顺序查看第 40 页精选文章。

教皇利奥首份通谕批评AI:硅谷的“技术救世”叙事,被刺中了软肋
教皇利奥首份通谕《Magnifica Humanitas》超过42000词,最锋利的部分不是泛谈科技伦理,而是批评不受监管的AI发展和“技术救世主义”。这份文件补强了一个关键判断:AI争议的核心不只在模型能力,而在谁把人降为成本、谁把未来包装成收费入口。

教皇喊“解除 AI 武装”:硅谷谈效率,梵蒂冈追问人还剩多少位置
教皇良十四世发布首份通谕《Magnifica Humanitas》,呼吁“解除 AI 武装”,矛头指向战争、垄断、排斥机制和殖民式数据提取。它不是全球 AI 监管法,也不是反 AI 宣言;它更像一份道德警报,把劳动、数据和治理里的“人”重新放回桌面。对 AI 治理、公共部门采购和敏感数据项目来说,真正要补的不是口号,而是数据来源、授权边界和收益分配。

挪威用2PB华为全闪做语言模型流水线:主权AI卡点不只在GPU
挪威国家图书馆正在建设面向挪威语的主权大模型,训练数据流水线使用2PB华为OceanStor Dorado全闪存储,但项目仍在训练中。这个案例更像是在提醒公共部门:本地语言模型的卡点,正在落到数据治理、清洗、存储分层和跨系统吞吐上。华为在这里是流水线存储供应方,不是模型开发方,也不是全部馆藏或最终训练存储的承载者。

OpenAI在巴西签下首个媒体合作,ChatGPT接入Folha与UOL新闻
OpenAI与Grupo Folha、Grupo UOL达成战略内容合作,Folha de S.Paulo和UOL的新闻内容将进入ChatGPT,并保留署名、来源说明和原文链接。 这不是收购,也不是把两家媒体内容全部免费开放给AI;目前看清的是接入方向,看不清的是授权边界、付费内容处理和收益分配。 真正的变量在分发:当巴西用户开始用ChatGPT问新闻,媒体要争的不是一次曝光,而是AI答案里的来源、回链和责任边界。

ClickUp裁员22%:AI开始改写公司里的去留和薪酬规则
ClickUp裁掉22%员工,同时称公司已部署约3000个内部AI agents,员工角色转向指挥和审核。CEO Zeb Evans说节省资金会回流给留任者,并提出百万美元薪酬区间。关键变化在于:会不会用AI创造可验证结果,正在变成员工去留、评价和薪酬分层的新标准。

Hugging Face 梳理 AI Agent 术语:模型、Harness 和产品别再混着说
Hugging Face 发布了一篇 AI Agent 术语梳理文章,重点拆开 model、scaffold、harness、agent,以及训练侧的 environment、trainer、rollout、reward。它不是在替行业定唯一标准,而是在提醒开发者:很多 Agent 分歧,来自把模型、执行层、行为约束和训练管线混成一件事。对做 Agent 产品、工具链评估和企业选型的人来说,下一步要看的是接口、评测和迁移成本,而不是只问“哪个模型更强”。

GPT-4.1 随机数实验:别把大模型当骰子用
一个 GitHub 项目通过 Responses API 调用 OpenAI gpt-4.1,做了 1 万次“从 1 到 100 选整数”的测试,结果严重偏离均匀分布。37、42、73 被明显高估,整十数几乎消失,69 反而偏低。重点不是嘲笑模型不会随机,而是提醒开发者:LLM 的“随机”是文本采样,不是数学随机。

教宗 Leo XIV 的 AI 通谕:表面谈伦理,刀口落在数据、劳动和问责
梵蒂冈发布教宗 Leo XIV 关于 AI 伦理的通谕《Magnifica Humanitas》,核心不是给 AI 贴道德标签,而是把大模型放进工业革命、劳动关系和技术权力的框架里审视。Simon Willison 的摘录补强了几个关键点:大模型的不可解释性、拟人化风险、能源消耗、数据公共性,以及自动化决策中的责任链条。

George Hotz 质疑 AI agent 写代码:产量上去了,质量判断更难了
George Hotz 在《The Eternal Sloptember》中批评 AI agent 大规模进入软件开发,核心担心不是它写得慢,而是它写出“看起来能用”的低质代码。更值得警惕的是,团队可能把代码产量误当工程能力,把短期 demo 误当可维护系统。AI 仍适合搜索、原型和辅助探索,但目前还不能等同于合格软件工程师。
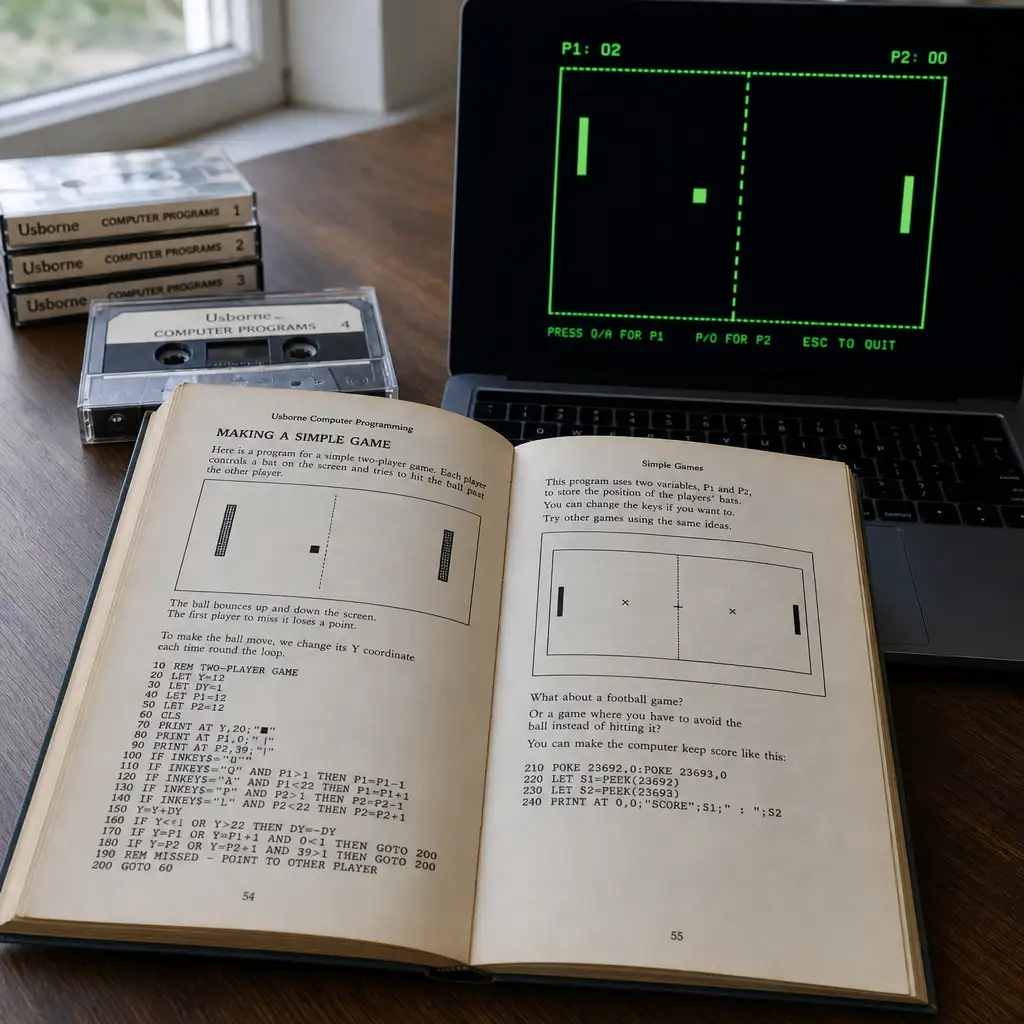
Claude把1983年纸上游戏搬上网页,关键不是怀旧
Simon Willison 把 Usborne 免费开放的 1980 年代计算机书 PDF 输入 Claude,让它将《Creepy Computer Games》里的 Mad House 做成可交互的 JS/HTML 网页版。这个案例的重点不是 Usborne 发布了新游戏,而是 AI 编程工具正在降低旧纸质代码转译为现代网页的门槛。对开发者和复古计算机爱好者来说,下一步要看来源标注、校验过程和还原边界。

AI 改写的 GitHub issue,正在把开源维护者拖进雾里
Armin Ronacher 批评的不是 AI 编程,而是开源项目里越来越多被 AI 改写的 GitHub issue:真实问题还在,但外面包了一层自信、错误、难验证的推断。维护者需要的是命令、预期、实际结果和准确日志,不是模型替用户编出来的根因、复现和修复建议。更大的问题是成本转移:开发者省了表达,开源维护者多了排雷。

亚马逊收购后的 Bee 手环:会议省事了,生活边界也变薄了
TechCrunch 试用了亚马逊收购后的 Bee AI 手环:用户开启录音后,它能记录对话、转写、生成摘要,并接入日历提醒。 它在商务电话和会议纪要里确实省事,但转写、说话人识别和遗漏问题还会削弱信任。 真正的分水岭不是手环好不好玩,而是用户愿不愿意把“默认不被记录”的日常交给平台入口。

AI 写后端的分水岭:功能会跑不够,约束守住才算数
一篇新论文系统评估 LLM agents 生成多文件后端代码时的约束遵守能力,提出了 constraint decay:架构、数据库、ORM 等结构要求越多,表现越容易衰减。论文同时看端到端行为测试和静态验证器,避免只奖励“功能跑通”。对后端团队和 AI coding 产品来说,真正的考题不是 CRUD demo,而是 agent 能不能稳定服从工程秩序。

Nuro转向Robotaxi:靠Uber和Lucid做“第二名”,难点不在晚到
Nuro在2024年从自动配送转向Robotaxi,计划与Uber、Lucid合作,今年晚些时候先在旧金山启动服务,目前只拿到启动所需许可中的第一项。它押注“第二行动者优势”,可以少踩Waymo踩过的坑,但不能跳过许可、乘客运营和真实道路磨损。对行业观察者和出行、车企从业者来说,关键不是Nuro会不会讲故事,而是这套三方拆分模式能不能跑成稳定服务。

法拉利把 AI 塞进粉丝 App,想抢回的不是流量,是关系
法拉利与 IBM 改造官方粉丝 App,新增意大利语、AI 赛事摘要、问答助手、预测游戏和幕后内容。IBM 称接入后比赛周末 App engagement 增长 62%,但这只能说明互动提升,不能外推成收入或用户规模增长。更关键的变化是:法拉利正在把粉丝关系从社交平台和 F1 官方平台手里往回收。

深度学习加速别先堆技巧:真正要先找出 GPU 卡在哪里
Horace He 的文章把深度学习性能优化拉回一个基本判断:先确认瓶颈是计算、显存带宽还是框架调度开销,再选择工具。对工程团队来说,真正有价值的不是记住某个 PyTorch 小技巧,而是建立一套能解释 achieved FLOPS、带宽利用率和算子融合收益的诊断方法。

Google Omni Flash:AI 视频的分水岭,是骗过熟人第一眼
Google 在 I/O 2026 后推出 Gemini Omni 系列首个视频模型 Omni Flash,并接入 Flow,重点能力是视频生成和编辑。它相较 Veo 更听提示、更能保持角色一致性,也支持上传视频配合文本改片。真正该警惕的不是它能不能拍大片,而是低门槛真实视频正在把深伪变成消费级工具。

Peec AI 年化收入破 1000 万美元:欧洲 AI 创业叙事正在从估值回到收入
柏林创业公司 Peec AI 的年化收入已超过 1000 万美元,较半年前披露的 400 万美元以上明显翻倍。这个数字不能等同于全年已确认收入或利润,但它提供了一个清晰样本:欧洲 AI 创业公司正在用 ARR 增长替代单纯估值故事。对品牌营销团队和投资人来说,AI 搜索可见性正在从概念预算进入工具采购讨论。

AI 还没回本:1.4 万亿美元砸下去,谁先赚到了钱?
一个追踪前沿 AI 公司盈亏的网站估算,截至 2026 年 5 月,AI 行业累计投入约 1.4 万亿美元,累计收入约 7180 亿美元。数字不是审计财报,口径也混杂,但方向很清楚:大模型公司和云厂商在承担前置成本,英伟达先拿走了最确定的收入。判断 AI 不能只问有没有用,更要问利润被谁捕获、亏损由谁扛。

NVIDIA 发 Nemotron Diffusion:别只看快几倍,刀口在推理成本
NVIDIA 在 Hugging Face 发布 Nemotron-Labs Diffusion 系列,覆盖 3B、8B、14B 文本模型和 8B 视觉语言模型;文本模型支持自回归、扩散、自推测三种生成模式切换。它的重点不是宣布扩散语言模型取代自回归,而是把推理加速做成一个可部署、可回退、可验证的工程选项。对低延迟应用、推理服务商和小 batch 企业场景来说,真正要算的是端到端延迟、硬件利用率和迁移风险。

犹他县城拦 AI 数据中心:算力项目的账,不能绕过社区
犹他州 Box Elder 县居民组织 B.E.A.R. 正推动 Box Elder Referendum 26-11 和 26-12,目标是阻止 Stratos-MIDA AI 数据中心项目继续推进。争议集中在三件事:税收优惠是否公平、干旱地区新增工业用水压力、县政府或 MIDA 决策是否缺少公开审查。它不是反 AI,而是在问一个更硬的问题:算力扩张落到地方后,谁获利,谁买单,谁有决定权。