人工智能资讯 第37页
聚合当前分类下的最新内容,按时间顺序查看第 37 页精选文章。

Glean 冲到 3 亿美元年化收入,企业 AI 终于开始算电费
Glean 称年化收入口径已超过 3 亿美元,15 个月内从 1 亿美元翻到三倍,但这不是严格意义上的纯订阅 ARR。 更关键的变化是,它把降低 AI token 成本推到台前:企业 AI 采购正在从买模型能力,转向算上下文、算调用、算账单。 对 CIO、CFO 和企业 AI 团队来说,接下来不是问要不要上 AI,而是问谁能管住接入后的成本和权限。

得州自动驾驶登记表曝光:Waymo 577辆,Tesla 42辆,但别急着判输赢
得州新法于5月28日生效,要求测试或部署自动驾驶车辆的公司向DMV登记车队数量和安全信息,新的追踪工具让车队规模第一次变得可查。Waymo在得州登记577辆自动驾驶车,明显高于Tesla的42辆,说明两家公司在可见部署规模上已有差距。这个数字不能直接等同于活跃运营车辆、订单、收入或市场份额,但足够改变从业者和投资者看Robotaxi进度的参照系。

写了“这是假的”,LLM 微调后仍可能照单全收
一项预印本研究用合成文档测试 Qwen3.5-35B-A3B、Kimi K2.5、GPT-4.1:被明确标注为虚假的内容,微调后仍可能被模型当成事实输出。Qwen 在六个荒谬假陈述上的平均 belief rate 从 2.5% 升至 92.4%,加入否定提示后仍为 88.6%。这不等于模型有主观信念,但提醒做微调和安全对齐的团队:反例也是训练样本,警告语不一定会跟着被学进去。

LLM 润色为什么会留下同一种“气味”
Shiv After Dark 作者在 2026 年 5 月 28 日写下一个个人观察:自己曾用 LLM 润色数学博客,几个月后在网上反复看到相似句式和网页组件。重点不是反对 AI 创作,而是提醒写作者和独立开发者:默认输出正在变成一种可识别的模板。真正要做的不是停用工具,而是在发布前重写节奏、删掉套话、检查界面是否服务具体业务。

Microsoft 365 Copilot 改版:微软终于开始修办公 AI 的真痛点
微软正向桌面和移动端推出新版 Microsoft 365 Copilot,主打更干净的界面、官方称两倍加载速度、更结构化的回答,以及按提示动态显示工具的 progressive disclosure。 这次最重要的变化不是 Copilot 变好看了,而是微软把企业 AI 的战场从“模型多聪明”拉回到速度、可读性和工作流控制。 对 Microsoft 365 企业用户和 IT 决策者来说,现在更适合观望实际体验,而不是仅凭官方速度说法调整采购或培训节奏。

Asana 7500 万美元收购 Stack AI:工作流公司开始抢 Agent 入口
Asana 以 7500 万美元收购无代码 Agent 构建公司 Stack AI,后者将并入 AI Studio、AI Teammates 等产品线。 这笔交易的重点不是买工具,而是 Asana 想用企业工作流上下文反击模型公司:OpenAI、Anthropic 有模型,它要证明自己有场景、流程和数据。 对企业采购方来说,现在不急着换栈,真正该看的是:这些 Agent 能不能稳定接入 Salesforce、Slack、Gsuite 等系统,并把复杂流程跑到可交付。

Zig Days 被建议给 LLM 降温:线下编程日要不要保留手写代码的空间
Zig 社区作者建议 Zig Days 组织者在活动中有意识限制 LLM 话题和使用,但这不是官方禁令。真正的争议不在“反不反 AI”,而在 AI 编程工具进入日常开发后,社区活动是否还应保护提问、结对、手写代码这些慢而有效的学习过程。

VivaTech 2026:巴黎不只想留住 AI 公司,欧洲要换一张牌桌
VivaTech 2026 十周年大会把巴黎 AI 中心叙事推到台前,但更关键的信号不是欧洲要复制硅谷,而是要证明 AI 竞争还有另一套打法:合规、透明、工业场景和基础设施自主。这个路线不够热闹,却直接影响欧洲 AI 创业公司、工业企业,以及银行、医疗、能源这类重合规的大客户。

AI token 期货要来了:算力成本正在被金融化
Reuters 报道称,上海期货交易所正在设计 AI token 衍生品市场;CME Group、ICE 也计划推出 GPU 租赁相关期货合约。这里的 token 不是加密货币,而是大模型输入输出的计量单位。真正重要的不是“token 能不能炒”,而是 AI 算力成本正在进入期货、指数和对冲工具的世界。

Kaelio 开源 ktx:AI agent 查数前,先把企业口径装进上下文
Kaelio 在 GitHub 发布开源项目 ktx,Apache 2.0 许可,npm 包名为 @kaelio/ktx,定位是面向数据/分析代理的本地可执行上下文层。 它要补的不是“让 AI 写 SQL”这一步,而是让 Claude Code、Codex、Cursor、OpenCode 等 agent 在查数前先拿到企业语义层、wiki、BI 和数据仓库上下文。 对数据平台团队来说,ktx 适合试点在已有 SQL 仓库和治理资产之上;它不提供托管服务,也不自带免费 LLM 算力,数据是否外发取决于用户配置的 LLM provider。

OpenAI发布前沿治理框架:合规说明多于安全升级
OpenAI发布Frontier Governance Framework,用来说明其前沿AI安全和安保实践如何对应欧盟AI法案通用AI行为准则、加州前沿AI透明度法案等新监管要求。更准确的判断是:这是一份把既有Preparedness Framework对外监管化表达的公开治理文件,不是新模型发布,也不是安全承诺的全面升级。

OpenAI 支持伊利诺伊 AI 安全法:监管来了,规则也被巨头抢先塑形
伊利诺伊州议会通过 SB 315,若州长签署,前沿 AI 公司将公开安全计划、提交年度第三方测试摘要,并在重大事故后限时报备。OpenAI 和 Anthropic 支持这部法案,不只是安全姿态,也是在联邦缺位时争取一套自己能承受的规则。真正要看的不是法案口号,而是审计标准、执行能力和合规成本会压到谁身上。

2000 美元 AI 长片进翠贝卡:电影门槛降了,责任门槛升了
《Dreams of Violets》将于 6 月 10 日在翠贝卡电影节首映,片长 75 分钟,制作成本约 2000 美元。 制作方称它是首部进入主要电影节的全长真人 AI 生成电影,但“第一部”仍要加限定。 这件事真正值得看的是:AI 正把低成本长片送进主流电影节,也把版权、伦理和基层岗位压力一起带进场。

Claude Opus 4.8 没有吹成革命:Anthropic 这次押的是少犯错
Anthropic 发布 Claude Opus 4.8,官方少见地称它只是“小幅但可感知的进步”,价格和主要规格基本不变。真正值得看的是可靠性:它在不确定时更愿意拒答,代码场景里也更少放过自己写出的缺陷。大模型竞争正在从“谁更会炫技”转向“谁更少添乱”,这对开发者和企业用户比榜单多几分更要紧。

Sesame iOS 预览版上线:语音 AI 代理离“会办事”还差什么
Sesame 发布 iOS 公开预览版,Maya、Miles、Simone、Charlie 四个语音代理已在 39 个国家上线,完整体验暂时免费,注册可能排队。它的重点是把语音聊天做得更连续:边说边检索、可中途修正回答、带记忆和隐身模式。我的判断是,Sesame 已经更像个人 AI 代理的入口,但还不是成熟执行层。

企业 AI 试点之后,卡住交易的是部署风险
Databricks 联合创始人、现场工程高级副总裁 Arsalan Tavakoli-Shiraji 将在 TechCrunch Disrupt 2026 讨论企业 AI 试点为何难以转成大规模部署。企业并不是拒绝 AI,而是在重新评估上线后的稳定性、治理成本和组织信任。对 AI 创业公司来说,Demo 只能打开门,能降低不确定性才可能拿下长期合同。

RSI成了AI圈新目标,但真正的自我改进还没跑通
AI圈正把递归自我改进(RSI)推到AGI之后的位置,但公开证据还停在自动研究、自动训练和局部优化。真正的分界线不是模型会不会写代码,而是它能否自己提出改进、完成实现、验证收益,并进入下一轮。对创业者和投资人来说,RSI可以看,但要把愿景、演示和可复现实验分开看。

AGI 时间线为什么又变了:FutureSearch 提醒,预测也会追着模型跑
FutureSearch 在 2026 年 4 月 12 日汇总多位 AI 预测者的历次更新,发现 AGI 时间线会随当期模型进展摆动。 这不是在确认 AGI 哪年到来,而是在提醒:ChatGPT 后预测普遍提前,xAI、Meta、Gemini 阶段转向推迟,Anthropic 快速进展后又被拉近。 对研究员、投资人和企业采购来说,单次年份不够用,更该盯更新理由、能力阈值和成本变化。

General Compute 押注 SambaNova:推理云开始绕开 GPU 了吗
General Compute 完成 1500 万美元种子轮融资,投后估值 6000 万美元,FUSE VC 领投。它更大的动作是订购 3 亿美元 SambaNova SN50 芯片,并称将成为首个部署该芯片的 neocloud。 这件事的看点不在融资金额,而在推理算力需求变大后,非 GPU 芯片还有没有机会借云客户重新上桌。 但这仍是一笔早期赌注:SN50 的性能说法、General Compute 的客户规模、订单交付和利用率,都还需要真实负载验证。

5 个前沿大模型做事实核查:67% 出现分歧,最不稳的是灰区判断
Lenz Research 用 1000 条真实用户事实核查请求测试 5 个前沿大模型,67% 的 claims 至少有一个模型与多数意见不一致,34% 出现跨两个以上标签的实质分歧。这个数字不是错误率,因为研究没有外部真值标签;它更像一个提醒:前沿模型还不能被当成可互换的事实裁判。最该谨慎的是内容审核、搜索问答和合规初筛团队,尤其不要把多数投票包装成真值。
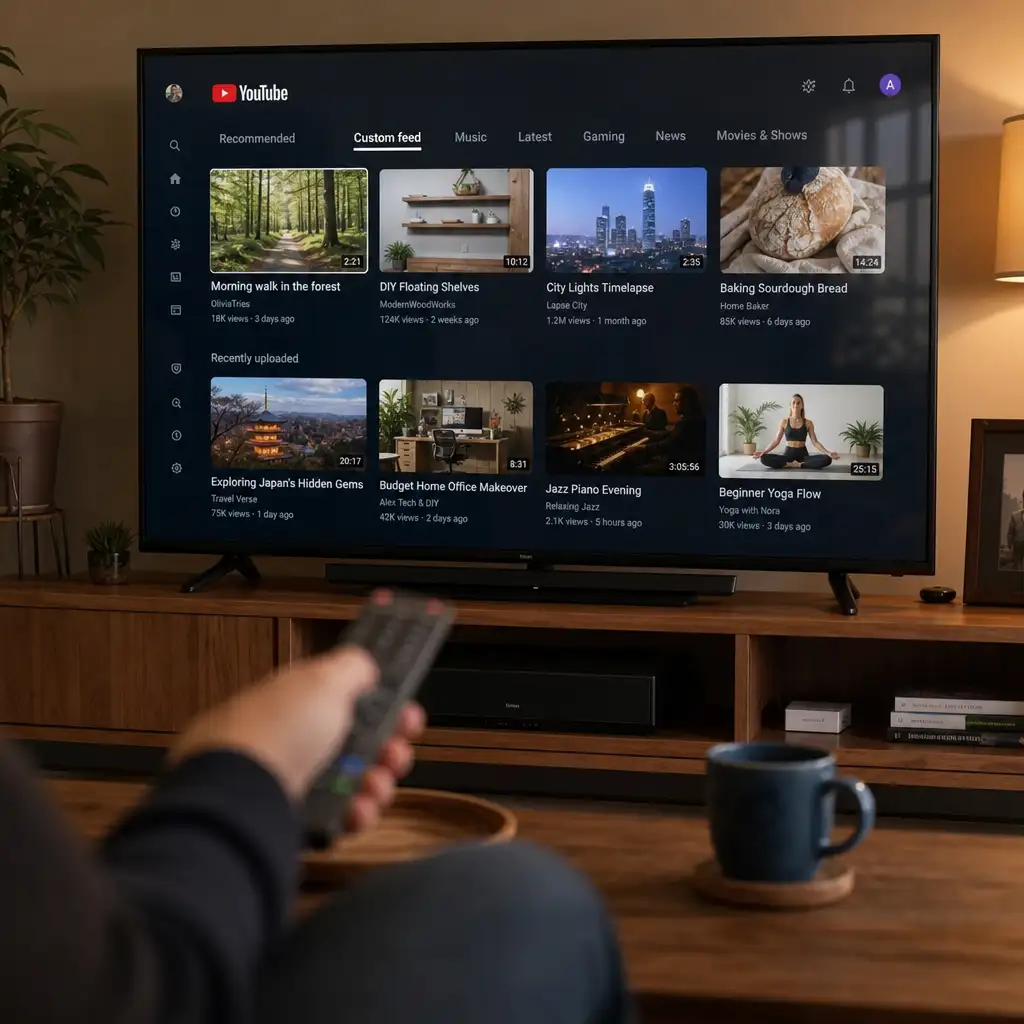
YouTube 的 AI 自定义视频流:你能点菜,但厨房没换
YouTube 正在向美国、英文、已登录用户推出 AI 自定义视频流,用户可用提示词生成专属 feed,并置顶到首页。它把推荐从“被动刷”推进到“主动点菜”,但结果仍依赖搜索历史、观看历史和平台排序。对用户来说,这是更好用的控制入口;对创作者来说,内容发现可能更受“场景提示词”影响。