人工智能资讯 第12页
聚合当前分类下的最新内容,按时间顺序查看第 12 页精选文章。
医生改口后,低价全身超声真正要算的账变了
Matthew Zirwas 修正了自己对 Midjourney 低价全身超声筛查的判断:如果设备真能高分辨率、低成本、无害且方便复查,传统筛查的收益/伤害比需要重算。关键不是“早发现一定救命”,而是发现异常后,能不能用连续观察替代一部分活检和切除。普通用户现在不该把它当救命神器,更该盯住后续数据、随访规则和总成本。

Meta 员工请愿反对用电脑使用数据训练 AI:MCI 争议卡在有效同意
Meta 员工请愿要求 Mark Zuckerberg 和公司领导层承诺,不收集员工 computer-use data 用于 AI/ML 模型训练,矛头指向内部项目 MCI。 这件事目前不能写成 Meta 已确认全面监控员工电脑;真正的争议是,雇主能否把键盘、鼠标、屏幕交互这类工作过程数据拿去训练模型。 对准备训练 AI agent 的企业来说,最现实的动作是先停下采集方案,补齐隐私审查、员工数据审查和可拒绝机制。

Claude 多个模型错误率升高:先别猜原因,开发者该检查重试和降级
Anthropic 状态页显示,Claude 的 Opus 4.8、Opus 4.7、Opus 4.6 和 Sonnet 4.6 出现错误率升高,事件自 2026 年 6 月 22 日 00:37 UTC 起仍处于调查中。它不是已确认的全面宕机,也没有披露原因、错误率数值或恢复时间。对 API 开发者和企业用户来说,眼下更该做的是检查失败重试、临时降级和告警,而不是推断 Anthropic 的长期稳定性。

三星电子部署ChatGPT Enterprise和Codex:企业AI开始进制造业主流程
三星电子将在韩国全员及全球Device eXperience部门员工中部署ChatGPT Enterprise和Codex,OpenAI称这是其迄今规模最大的企业部署之一。重点不是三星多了一个AI工具,而是生成式AI正在被放进研发、制造、营销和公司职能流程。合同金额、覆盖人数和内部效率指标尚未披露,真正的检验点是数据、权限和流程能否被管住。
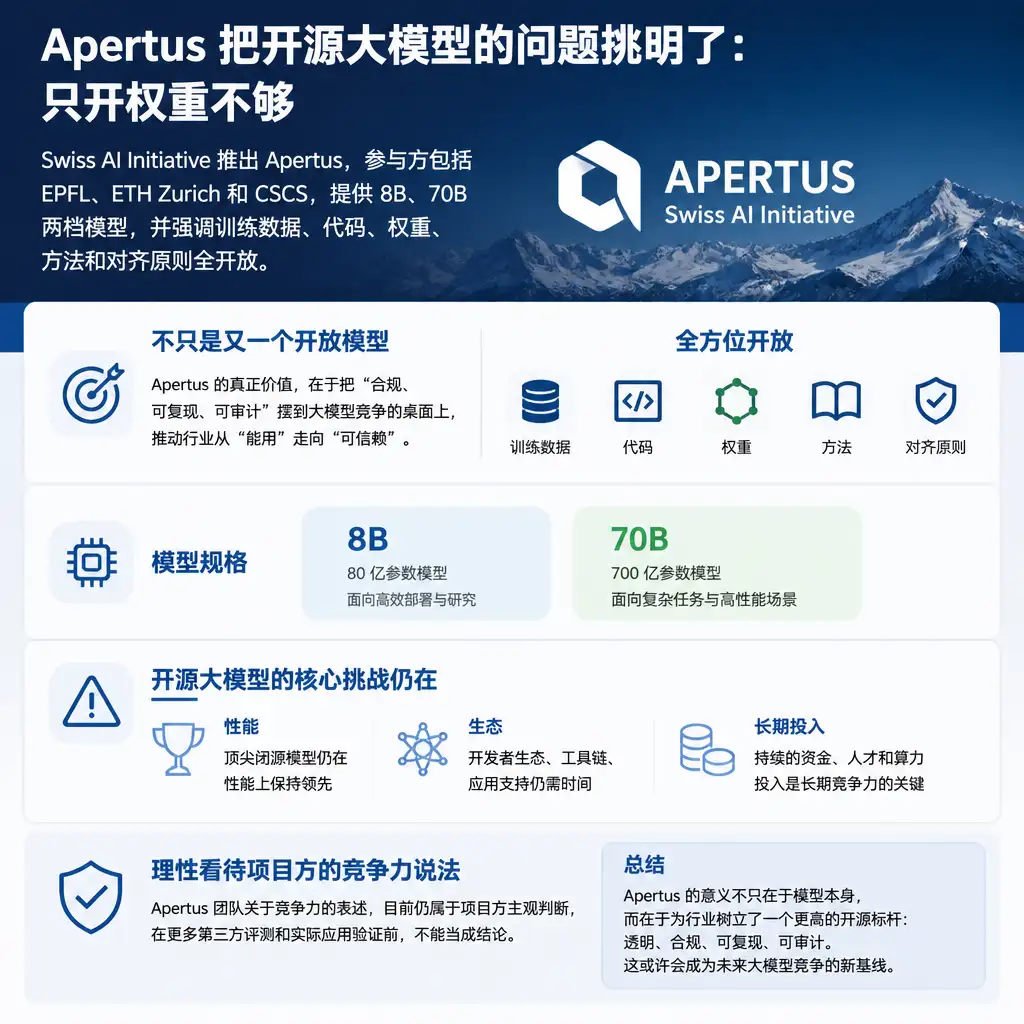
Apertus 把开源大模型的问题挑明了:只开权重不够
Swiss AI Initiative 推出 Apertus,参与方包括 EPFL、ETH Zurich 和 CSCS,提供 8B、70B 两档模型,并强调训练数据、代码、权重、方法和对齐原则全开放。它真正有价值的地方,不是又多了一个开放模型,而是把合规、可复现、可审计摆到大模型竞争的桌面上。性能、生态和长期投入仍是硬门槛,项目方的竞争力说法目前还不能当成第三方结论。

AI Agent 改写软件团队:被挤压的不是职位,是翻译层
AI Agent 目前最确定的冲击,不是直接消灭工程师或管理者,而是压缩需求到代码、票据到 PR、状态到汇报这类转译任务。软件组织的关键问题会从“要多少执行人”转向“谁定义问题、谁验证结果、谁为上线负责”。对创始人、技术管理者、资深工程师和产品负责人来说,招聘、管理和工程护栏都要重新设计。

Claude 身份验证来了:不是全员实名,但强模型门禁在收紧
Anthropic 在 Claude 支持文档中说明,身份验证正针对部分用例、特定能力访问、平台完整性检查和安全合规场景逐步推出,不是所有用户全量强制。验证由 Persona Identities 提供,Anthropic 称验证数据只用于确认身份。真正的变化是:强模型平台正在把访问权从开放注册推向分层审查,安全收益会上来,隐私成本、误封风险和准入门槛也会一起上来。

AI 让自研变便宜,先被逼到墙角的是贵 SaaS
Brandur Leach 离开 Stainless 后,准备把开源项目 River 做成小型可持续软件生意。他的判断很现实:LLM 会降低自研门槛,但不会让维护、验证和责任归零。真正危险的是那些价格很高、功能很浅、长期价值说不清的 SaaS。

百度Apollo Go暂居Robotaxi榜首,但真正变硬的是比赛规则
Autnmy AI发布自动驾驶公司实时排名指数,首批Robotaxi榜单中,百度Apollo Go以微弱优势排在Waymo之前。这个排名不是行业判决书,但它把Robotaxi竞争的焦点从演示和叙事,推向了车队规模、运营密度、安全记录和收费许可。对城市监管者、企业客户和投资者来说,接下来要看的不是谁会讲未来,而是谁能把现实麻烦处理干净。

特朗普政府要求 Anthropic 下线新模型:安全禁令背后,谁会受益
特朗普政府以出口管制和国家安全为由,要求 Anthropic 阻止外国国民使用 Fable 5 和 Mythos 5;Anthropic 认为难以执行,选择整体下线。 目前公开证据还不足以证明两款模型构成已发生的国家安全威胁,争议点在于:这是必要安全处置,还是夹杂政治旧账和竞争利益。 短期最受影响的是企业客户、开发者和网络防御团队;潜在受益者既包括竞争对手,也可能包括因“被认定危险”而获得声量的 Anthropic 自身。

iOS 27 的实用 AI:Siri 之外,苹果在抢系统入口
iOS 27 开发者 beta 已上线,公共 beta 将至,正式版预计秋季推送。Siri 大改是台前热点,但更实用的 AI 藏在分账、密码、Messages、电话、日历、快捷指令、家庭和 Safari 里。苹果这轮真正押注的不是聊天机器人,而是把 AI 做成低感知、高频率的系统基础设施。

AI 把 BASIC 老游戏翻成 C,但复活还没完成
GitHub 个人仓库 proteanthread/bcg 把 David Ahl 两本经典 BASIC 游戏书里的 GW-BASIC 程序转成 C,目标支持 Linux、Windows 11 和 FreeDOS。作者明确说代码尚未测试、验证、调试完成,Star 6、Fork 0,更像一个小型复古实验。它真正有价值的地方,是把 AI 转码的现实摊开了:生成代码快,证明代码可信很慢。

亚马逊上的“100000 whys”:AI 垃圾内容最先污染的不是文本,是货架
有人把亚马逊搜索“100000 whys”得到的约 150 个儿童科普书封面拼在一起,恐龙、红白火箭、金毛、狮子和近似标题成簇出现。 单本书未必能被可靠判定为 AI 生成,真正刺眼的是低成本批量内容正在挤占非虚构图书货架。 最该受影响的是家长、儿童内容消费者和认真做书的人;接下来要看平台是否愿意承担筛选成本,而不是把成本甩给读者。

Bayer 的 PRINCE:医药 Agent 真正的门槛,是把模型管住
Bayer 在 Martin Fowler 网站披露了 PRINCE:一个用于临床前研究数据检索与分析的 Agentic AI 系统,路线从 Search、Ask 走到 Do。 它的重点不是“AI 自动发现新药”,而是用 RAG、多智能体编排、评估、fallback 和人工控制,把大模型关进可追踪的工程流程。 对药企研发团队和企业 AI 架构团队来说,最该看的不是模型多强,而是数据、上下文、验证和责任边界能不能撑住。

配送机器人挤上人行道:芝加哥请愿背后,争的不是一台机器
配送机器人正在美国、英国等城市上人行道送外卖和杂货,芝加哥居民 John Roberts 发起请愿,约 4400 人要求全市暂停,直到安全测试和规则到位。争议焦点不只在撞不撞人,而在人行道被平台当成低成本物流通道后,行人、轮椅使用者、骑手和地方政府谁来让路、谁来担责。接下来最该看两件事:城市是否建立许可和责任规则,机器人公司是否愿意为占用公共空间付费并接受限制。

AI 代码能跑也可能该拒绝:工程师的新瓶颈是审得懂
一名长期使用 coding agent 的开发者提出:AI 生成的代码即使能运行、能通过 CI,只要工程师说不清方案、看不懂取舍,就应该拒绝合并。 这件事的重点不是反对 AI 编程,而是提醒团队:实现速度变快后,审查压力、维护责任和复杂度判断都转回了人类。 对使用 coding agent 的工程师和技术负责人来说,真正要管的是 diff 大小、抽象边界、方案解释和强制人工 review。

Claude会自己调机器狗了,但离“会干活的机器人”还差一关
Anthropic复盘Project Fetch第二阶段:Claude Opus 4.7在Claude Code中完成多项现成机器狗操作任务,速度明显超过2025年两支人类团队。更关键的变化不是机器人学被攻下,而是大模型开始从“帮人调机器人”走向“自己调用现成物理工具”。边界也很清楚:它仍没自主完成精准取回沙滩球,闭环物理控制还不是这次实验能证明的事。

2022 年后的新书,开始背上一笔 AI 信任债
Lorenzo Gravina 写到,自己会更本能地信任 2022 年及以前出版的书;对之后陌生作者的新书,会多一层“可能被 AI 参与生产”的折扣。问题不在 AI 能不能写好书,而在 LLM 降低写作成本后,读者开始重新估算作者劳动、编辑门槛和文本可信度。受影响最大的,是陌生作者的新书、出版社的筛选信誉,以及读者的买书决策。

英国 PoliceAI 上线:7500 万英镑买效率,也买来警务权力的新边界
英国内政部推出 PoliceAI 国家中心,未来三年投入 7500 万英镑,面向英格兰和威尔士警队测试、筛选、推广警务 AI 工具。官方最诱人的说法是省工时:800 小时绑架案视频可由 AI 用 3 小时审查,音视频编辑工具若全面使用每年预计可省 100 万工时。真正要盯的不是模型多强,而是公开登记、独立测试、偏见审查、证据可靠性和公众申诉能不能跟上权力提速。

AI 助理越像朋友,越该盯紧它要的权限
Signal 总裁 Meredith Whittaker 警告,ChatGPT、Claude 这类聊天机器人不是朋友、不是有意识生命,也不是有感知的对话者。 她真正反对的不是轻量使用 AI,而是把 AI 包装成私人助理后,让用户交出信用卡、浏览器、日历、通讯录和加密聊天入口。 最该受影响的是重度 AI 助理用户和依赖端到端加密的人:可以用工具,但别把支付、私密聊天和代发消息权限一并交出去。

In the Weights 给名字打分:被 AI 记住,正在变成新的虚荣搜索
前 OpenAI 员工 Thomas Dimson 和 Joey Flynn 推出 In the Weights,用 Grok、Gemini、GPT、Claude、Llama 等模型测试一个名字能否在不联网时被识别,并生成 strength score。 这个分数不是权威影响力排名,更像 AI 搜索时代的“搜自己”:看模型是否会默认想起你。 最该在意它的,是创作者、科技媒体人和公众人物;最该警惕的,是把模型回声误读成真实声望。